Administration Guides
Deploy a model using Rancher Apps Catalog
TODO déplacer côté admin
Grâce au graphique Helm inference service, vous pouvez déployer un modèle d'inférence avec Rancher.
Prérequis :
- Zot disponible dans la liste des registres de Rancher
- Instance mlflow déjà en cours d'exécution
- Serveur de modèles (kserve) déjà déployé
Find inference-service in Zot Registry
Dans Rancher, cliquer sur :
- Apps
- Charts
- select zot repository
- choose
inference-service - choose a name and a namespace
Complete arguments
- Engine: Le moteur du service d'inférence. Pour un modèle Transformers, c'est huggingface qui doit être utilisé.
- model URI: Le chemin d'accès au modèle. Cela inclut trois informations essentielles :
- le texte "mlflow-"
- Mlflow instance: Le nom du ClusterStorageContainer de l'instance Mlflow à cibler. Dans l'exemple ci-dessous, il s'agit de
test1. Vous pouvez exécuter une commande kubekubectl get ClusterStorageContainersur le cluster pour voir les options disponibles - Model name: Le nom du modèle enregistré à obtenir. Dans l'exemple ci-dessous, il s'agit de
test_fillmask - Model version: La version du modèle enregistré à obtenir. Dans l'exemple ci-dessous, il s'agit de
1.
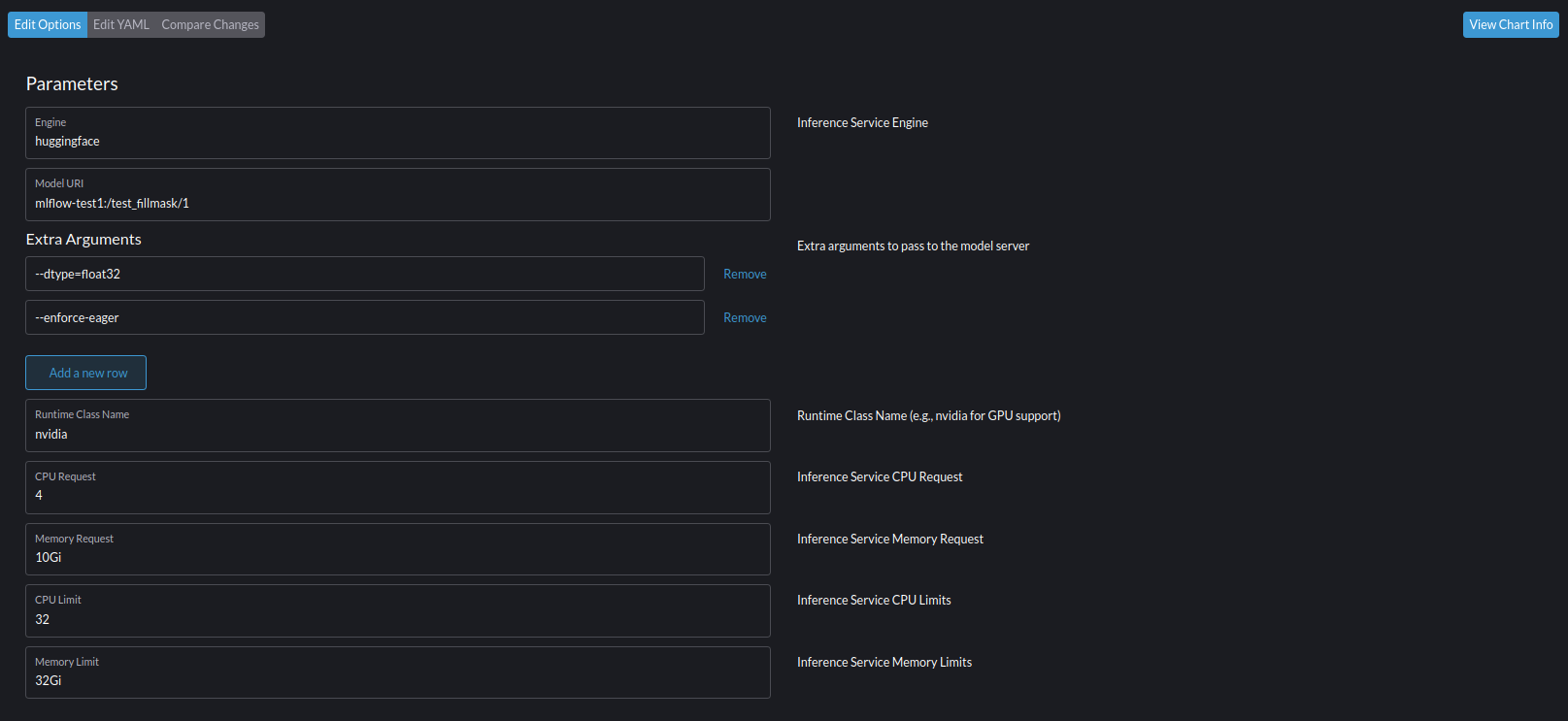
Cliquez ensuite sur le bouton « Installer ».
L'installation de l'application :
- télécharge un modèle déjà étiqueté depuis l'instance mlflow ciblée - le déploie pour l'inférence dans l'espace de noms spécifique demandé