Administration Guides
Etat du service Trino
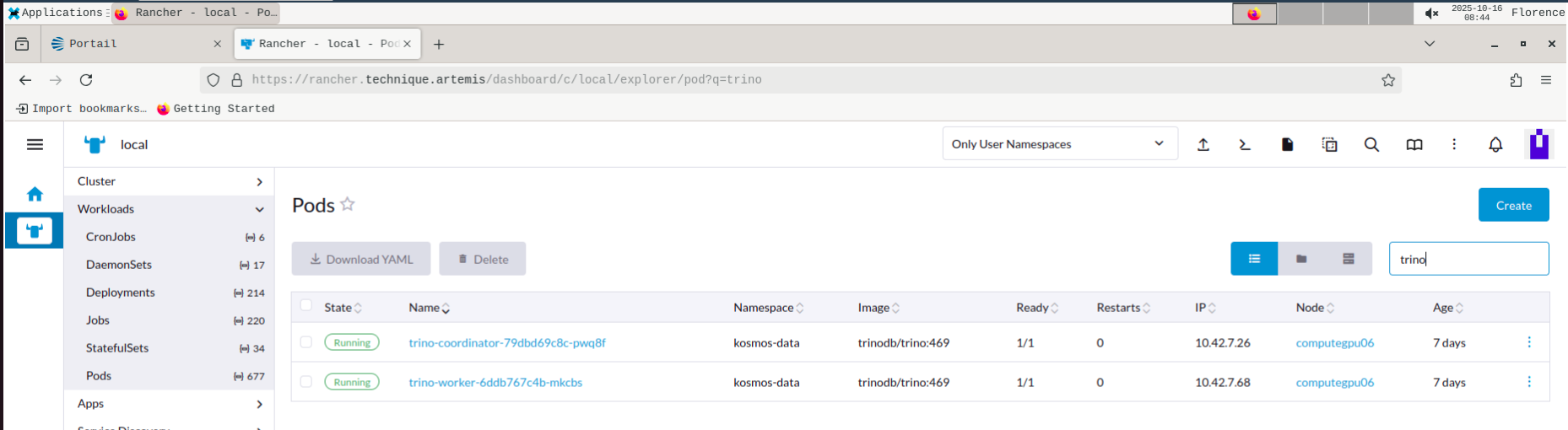
Les pods doivent être à l'état RUNNING.
Consulter les logs des pods
Vérifier qu’aucune erreur n’est présente dans les dernières lignes de logs des pods.
Modifier le mot de passe trino du compte d'accès
Le compte d'accès Trino qui est partagé entre l'administrateur système et l'administrateur data peut nécessiter un changement de mot de passe.
Pour cela, procéder en 2 étapes :
1/ Modifier le mot de passe dans le fichier password
Il faut tout d'abord générer le nouveau mot de passe haché (comme pour une création : cf. procédure de création du compte d'accès trino).
Via le dashboard rancher, sélectionner le namespace kosmos-data où se trouve Trino, aller dans More Resources / Core / Secrets, rechercher trino-password.
Accéder au trino-password-file, cliquer sur Edit Config, modifier la Value user:password haché de la Key password.db puis cliquer sur Save.
2/ Coté métier, modifier les connexions
Les accès via Trino sont principalement utilisés pour Superset. Pour tous les cas où l'accès à trino est réalisé avec le compte d'accès dont le mot de passe a été modifé, il sera nécessaire de venir modifier la connexion pour utiliser le nouveau mot de passe.
Par exemple, l'administrateur data aura été informé du nouveau mot de passe et il accède à Superset pour modifier la connexion à la database concernée (geste standard Superset).
Créer un catalogue Trino
Cette procédure permet de créer un catalogue trino qui donnera accès de façon unifiée (via requêtes SQL) aux EDS des différentes technologies disponibles dans l'infostructure.
La notion de catalogue va aussi nous permettre d'associer un espace de stockage (database dans PostgreSQL, bucket dans S3, index dans OpenSearch) à un utilisateur (ex: un datascientist). Cela va permettre de propager l'identité de l'utilisateur lors de la connexion à l'EdS lorsque l'EDS est protégé par une politique BEC.
Les étapes nécessaire dans Trino pour créer un catalogue et le mettre à disposition des utilisateurs métier sont :
- Créer les catalogues personnalisés si le BEC doit s'appliquer
- Associer le catalogue à un compte d'accès (et si besoin créer ce compte d'accès)
- Créer les vues si nécessaire dans le catalogue (utile pour s3 notamment)
Dans le schéma ci-dessous, l'ensemble du chemin d'accès depuis Superset jusqu'à l'EDS.
La présente procédure correspond à l'étape du milieu, effectuée dans Trino par l'administrateur sytème :
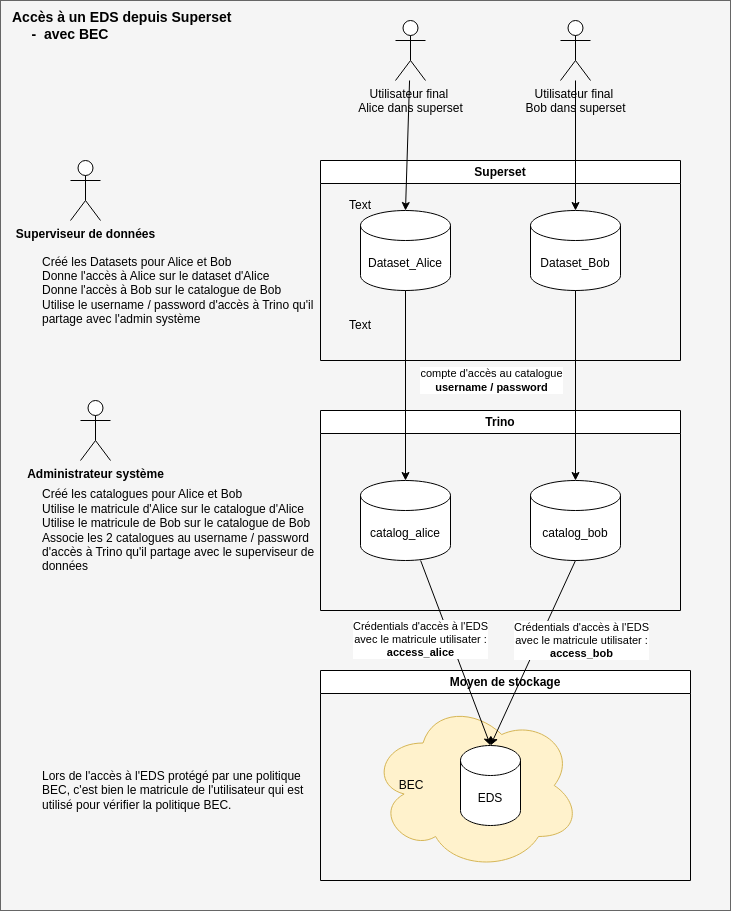
Etape 1 - Déclarer un catalogue
Un catalogue standard est créé lorsque l'EDS est créé. Si il n'y a pas de besoin d'appliquer une politique BEC, il est inutile de créer un catalogue personnalisé. On vérifiera juste la présence et le nom du catalogue standard.
Pour opensearch, il n'existe pas 1 catalogue par EDS mais 1 catalogue d'accès à l'ensemble du cluster métier opensearch unique "opensearch". Pour le BEC c'est ce catalogue qui doit être personnalisé.
La restriction d'accès à un index se fait dans superset par l'Administrateur données. Il ne sera pas possible de restreindre l'accès aux index pour l'utilisation du catalogue Trino opensearch depuis jupyter.
L'administrateur données doit être conscient de cette ouverture d'accès lorsqu'il fourni les crédentials d'accès au catalogue Trino opensearch à un utilisateur 'data'.
Si le BEC doit s'appliquer, il faut créer 1 catalogue personnel pour chaque utilisateur final (identifié par son matricule keycloak).
Pour ce faire nous avons besoin de connaitre :
- le nom de l'EdS cible ;
- le matricule (keycloak) des utilisateurs devant y accéder lorsque l'EdS est protégé par une politique BeC.
Les étapes pour créer un catalogue personnalisé sont :
-
Accéder à la console d'administration Rancher via le portail
-
Sélectionner le cluster kubernetes à modifier:
- Sélectionner le namespace :
kosmos-dataen haut à droite de l'écran.
- Modifier le secret
Cliquez sur la loupe, tapez secret et sélectionnez "secrets"

Cherchez le "trino-athea-catalogs" en haut à droite :

Il faut copier le catalogue standard de l'EDS (protégé par le BEC) et ajouter le matricule voulu (de l'utilisateur final qui accédera aux données) :
Cliquez sur les "..." et "Edit Yaml" pour dupliquer le catalogue standard puis "Edit Config" pour modifier le catalogue dupliqué (ajouter le matricule au champ qui correspond au user d'accès à l'EDS):
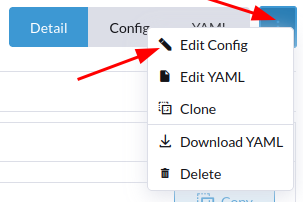
Puis :
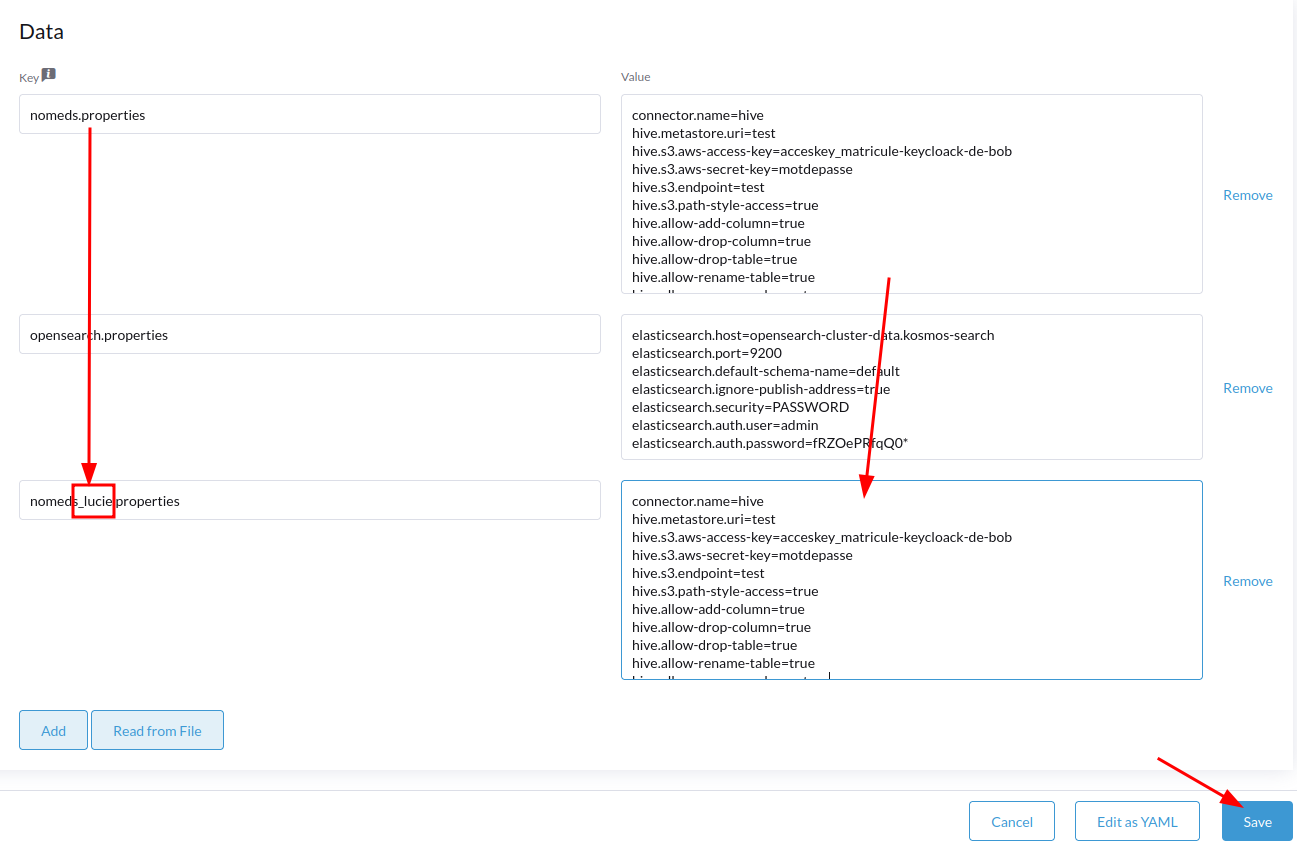
Chaque moyen de stockage dispose d'un modèle de catalogue spécifique au connecteur mis en oeuvre : voir ci-dessous. Ce modele contient les identifiants d'accès (idacces et mot de passe notamment).
Pour un catalogue S3
Il y a 1 catalogue par bucket
C'est l'"acces_key" qui doit être personnalisé :
connector.name=hive
hive.metastore.uri=thrift://hive-metastore.kosmos-data:9083
hive.metastore.username=postgres
fs.native-s3.enabled=true
s3.region=us-east-1
s3.aws-access-key= acceskey_matricule-keycloack-de-bob
s3.aws-secret-key= mot de passe
s3.endpoint=http://iad-s3-shared.kosmos-system-restricted.svc.cluster.local:9644
s3.path-style-access=true
hive.security=allow-all
Pour un catalogue PostgreSQL
Il y a 1 catalogue par database PG. A noter que la base de données précisée à la fin de l'URL (ici mabdd) doit exister au prélable afin que Trino ne renvoie pas d'erreur au moment d'utiliser le catalogue. Par défaut, PostgreSQL crée automatiquement trois bases de données : template0, template1 et postgres.
C'est le "user" qui doit être personnalisé :
connector.name=postgresql
connection-url=jdbc:postgresql://iad-pg-shared.kosmos-system-restricted.svc.cluster.local:9722/mabdd
connection-user= user_matricule-keycloack-de-lucie
connection-password= mot de passe
Pour un catalogue OpenSearch
Un catalogue OpenSearch unique est défini de base avec un compte technique Trino. Ce catalogue a accès à tous les index OpenSearch, ce qui est différent des bases de données S3 et PostgreSQL.
C'est dans superset que l'Administrateur de données va restreindre le droit d'accés à des index OpenSearch (procédure Déclarer les databases et les datasets dans Superset qui se trouve dans le DTU MU).
C'est le "user" qui doit être personnalisé :
connector.name=opensearch
opensearch.host=opensearch-cluster-data.shared-search.svc.cluster.local
opensearch.port=9200
opensearch.default-schema-name=default
opensearch.ignore-publish-address=true
opensearch.tls.enabled=true
opensearch.tls.verify-hostnames=false
opensearch.tls.truststore-path=/usr/local/certs/ca.crt
opensearch.security=PASSWORD
opensearch.auth.user=user_matricule-keycloack-de-bob
opensearch.auth.password=mot de passe
Redémarrer le service
Pour la prise en compte des catalogues créés, il faut relancer les déploiements trino-coordinator et trino-worker :
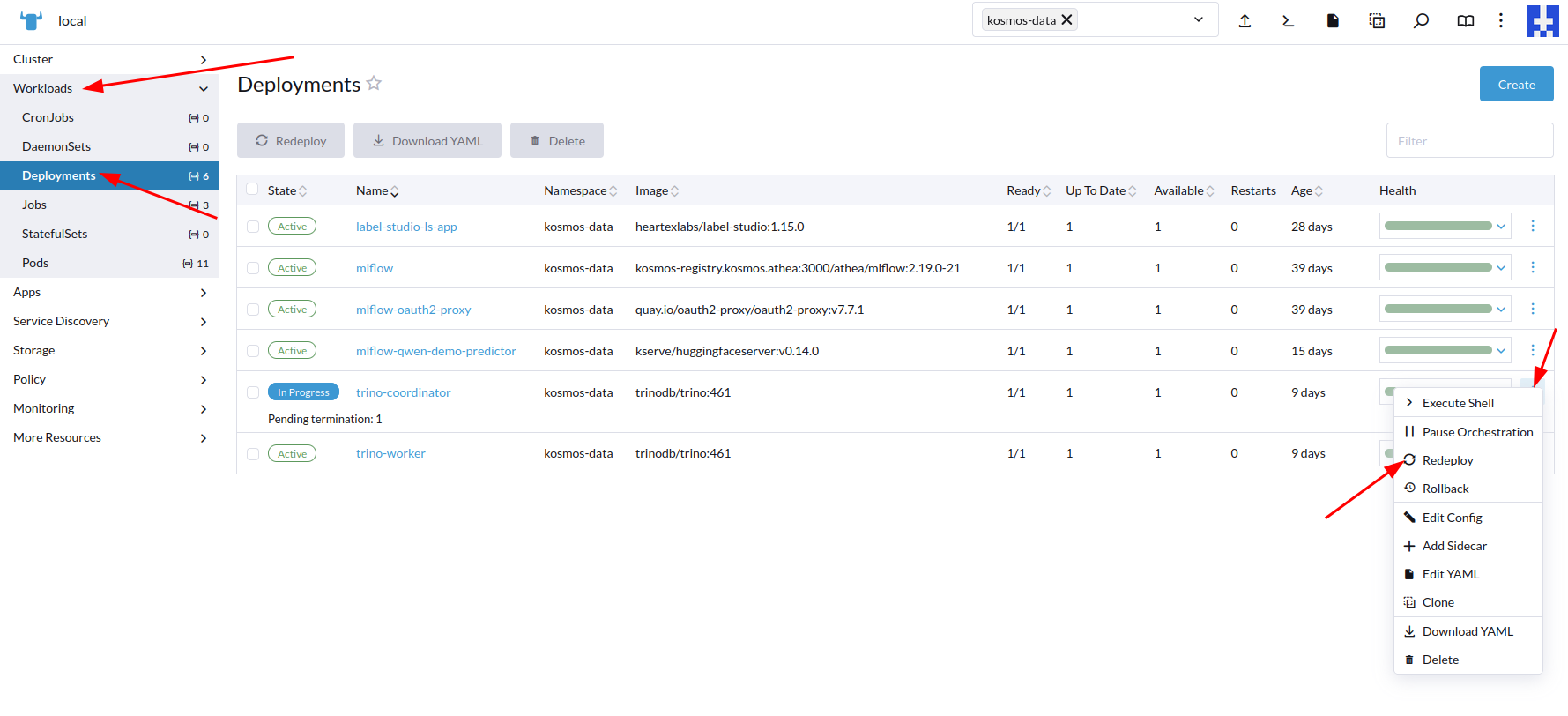
Etape 2 - Associer le compte d'accès (si besoin le créer)
Maintenant que nous avons notre catalogue, il doit être associé à un compte d'accès trino.
Le compte d'accès doit être créé dans le fichier des mots de passe de trino. Il est composé d'un 'user' et d'un 'password'.
Créer le compte et générer un mot de passe
Les mots de passe doivent être hachés de manière sécurisée à l'aide de BCRYPT ou PBKDF2.
Ne pas utiliser de caractères spéciaux dans les mots de passe ! D'une part il faudrait les encoder et d'autre part cela peut causer des problèmes de connectivité avec Superset, qui a tendance a mal les gérer.
L'utilitaire htpasswd est disponible dans l'infostructure, sur la VM spray (peut etre ajouté par un admin infra avec la commande sudo apt install apache2-utils) et permet de générer le mot de passe haché :
htpasswd -nbBC 10 username password
Dont le résultat est :
username:$2y$10$vgKhbN10nNxeAezPlmF2vurQm0xajDBqufMTRij2VbwvY/fIdCCzq
La deuxième partie après les deux points correspond au mot de passe haché, qui est unique.
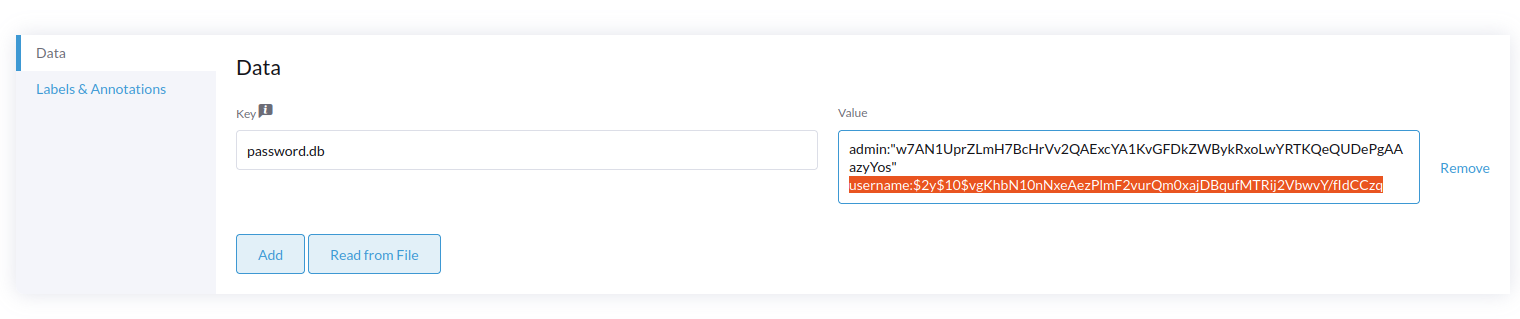
Ajouter dans le fichier password
Via le dashboard rancher, sélectionner le namespace kosmos-data où se trouve Trino, aller dans More Resources / Core / Secrets, rechercher trino-password.
Accéder au trino-password-file, cliquer sur Edit Config, modifier la Value user:password haché de la Key password.db puis cliquer sur Save.
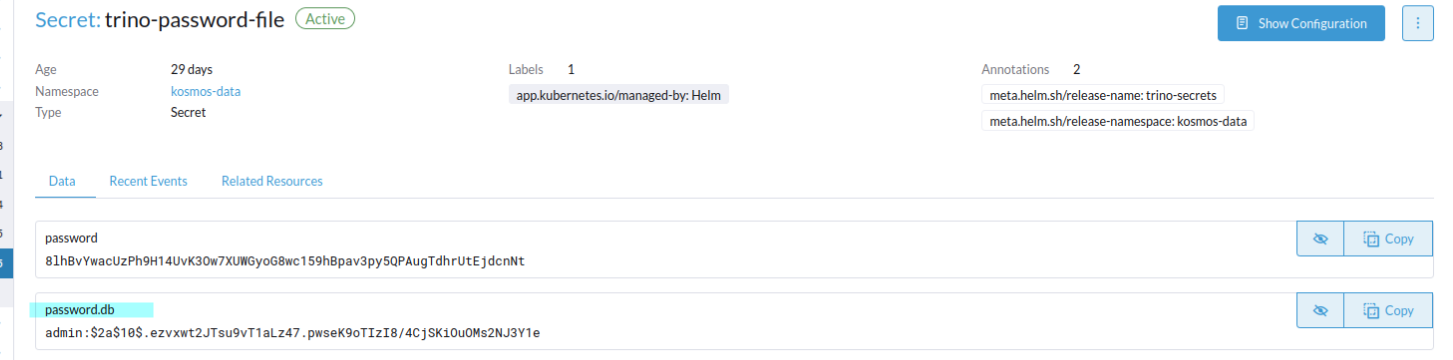
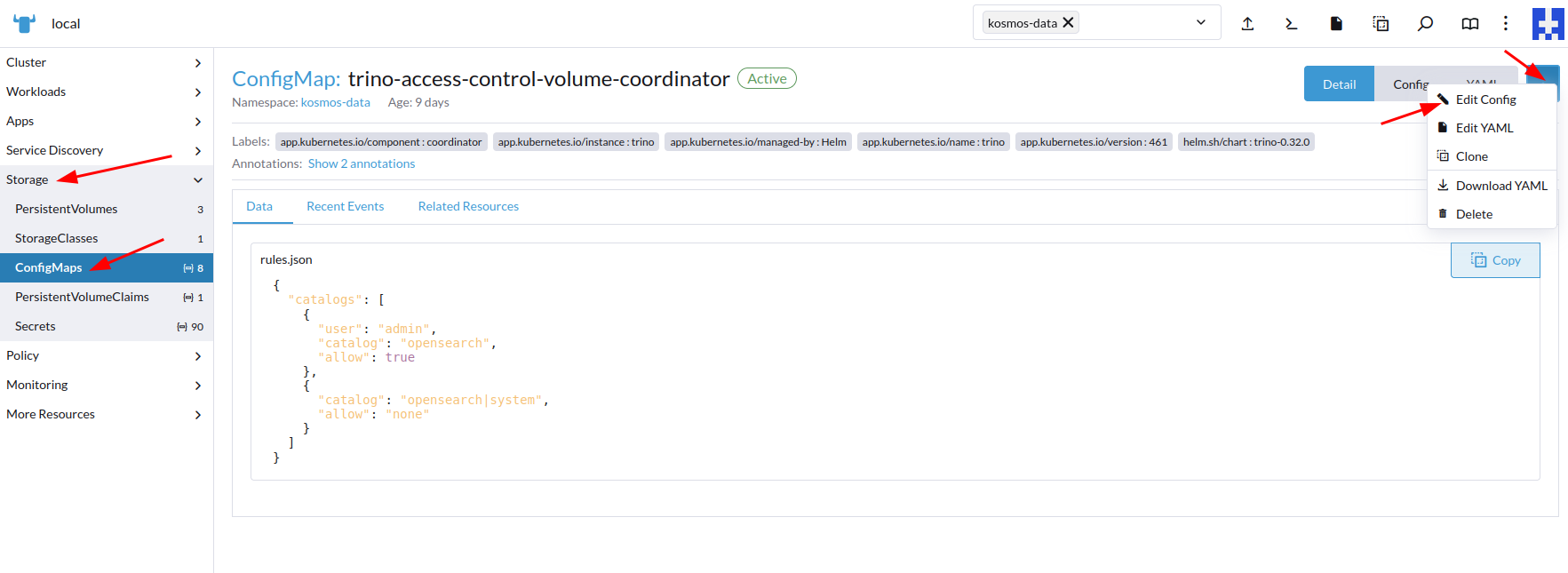
Associer le compte au catalogue
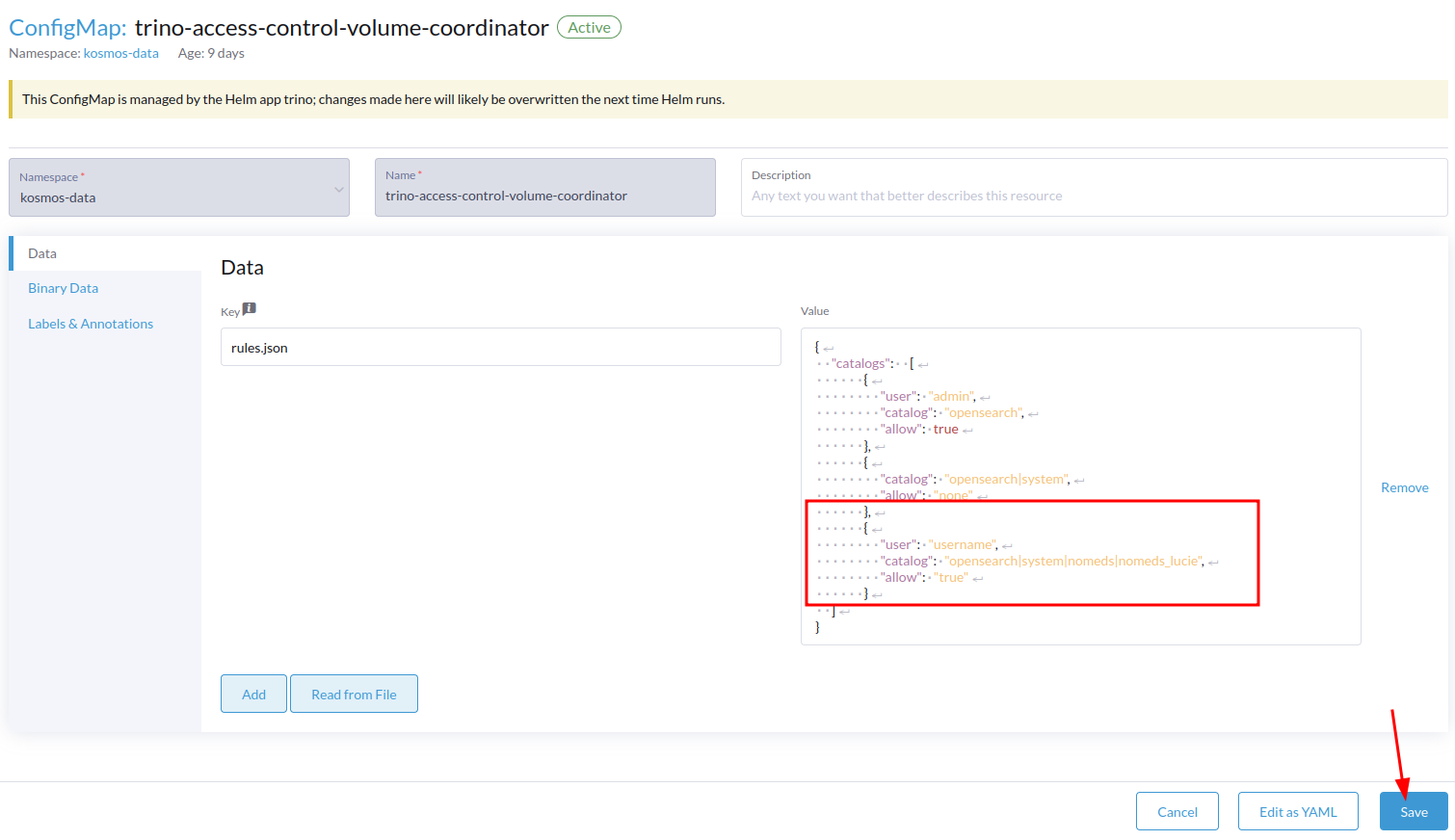
Rechercher le configmap trino-acces-controle-volume-coordinator et modifiez le :
Ajouter pour le nouvel utilisateur l'accès au catalogue system puis aux catalogues dont il a besoin (séparés par des | ).
Redémarrer le service
Pour la prise en compte des catalogues créés, il faut relancer les déploiements trino-coordinator et trino-worker :
Vérification dans trino
Pour vérifier que la création est correcte, accéder à trino : Via Rancher, dans le namespace kosmos-data, accéder à la liste des pods. Choisir le pod du trino-coordinator et cliquer sur le bouton d'exécution' :

Résultat : la console est ouverte pour utiliser les commandes dans le pod Trino :
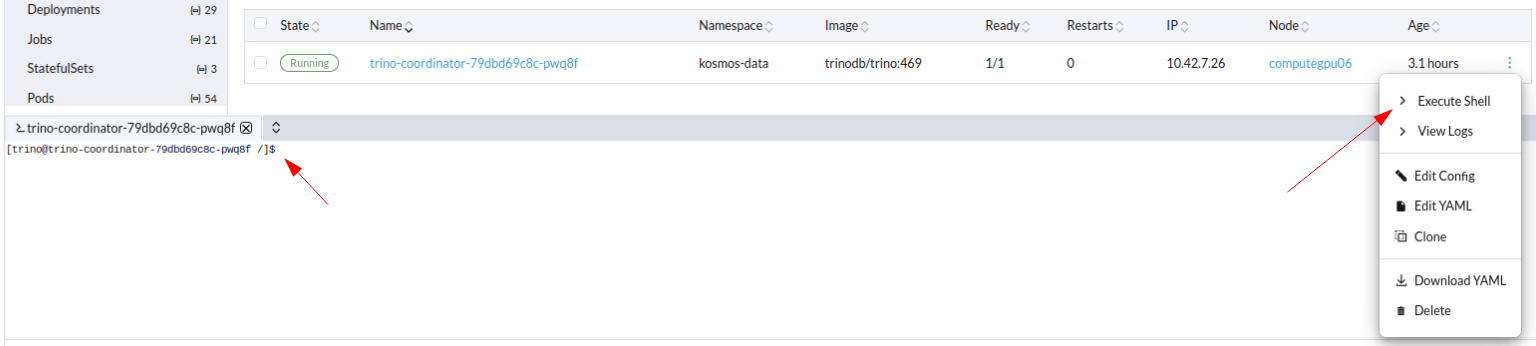
Accéder au catalogue créé
Pour notre exemple le nom du catalogue est nom_catalogue (nomeds_bob), le username (bob) et password (dont le hash associé est $2y$10$vgKhbN10nNxeAezPlmF2vurQm0xajDBqufMTRij2VbwvY/fIdCCzq).
trino --user='bob' --password=true --catalog='nomeds_bob' --server https://trino.kosmos-data:8443 --keystore-path=/usr/local/certs/tls-combined.pem
Après que le prompt de trino trino> s'affiche il faudra entrer cette commande:
SHOW CATALOGS;
Si la sortie n'est pas en rouge (ce qui signifie que c'est une erreur) la procédure s'est bien déroulée.
L'administrateur transmet à l'Administrateur de données le nom du catalogue créé et le compte 'user/password' associé, pour qu'il puisse donner le droit d'accès via Superset(procédure Déclarer les databases et les datasets dans Superset qui se trouve dans le DTU MU).
Personnalisation du catalogue (cas S3)
Pour requêter les données d'un bucket s3 qui contient des fichiers avec des données structurées, nous devons créer un schéma et une table qui décrit la structure des données, ci-dessous un exemple :
CREATE SCHEMA monSchema
WITH (
location = 's3a://nomdubucket/'
);
Ensuite nous devons aussi créer une table :
use monSchema;
Deux cas de figures, nous connaissons le nom de nos colonnes :
Create table nomtable (
codecommune varchar,
nomcommune varchar,
codepostal varchar,
libelle varchar,
ligne5 varchar,
coordonnees varchar,
confidentialite varchar
)
WITH (
external_location='s3a://nomdubucket/',
format = 'csv',
csv_separator = ';'
);
Nous ne connaissons pas le nom de nos colonnes (la table n'aura qu'1 champ : 1 ligne du fichier):
CREATE TABLE nomtable(
all_columns varchar)
WITH (
external_location = 's3a://nomdubucket/',
format = 'TEXTFILE',
skip_header_line_count=1);
Les formats "CSV" et "PARQUET" n'acceptent que les colonnes de type VARCHAR. Le format "TEXTFILE" accepte les différentes types de colonnes : VARCHAR, DOUBLE, INTEGER, ... Ci-joint une documentation sur les différents types de colonnes acceptés par Trino. (https://trino.io/docs/current/language/types.html)
Connexion à un catalogue trino
Cette procédure explique comment se connecter à un catalogue trino, afin de vérifier celui-ci ou bien d'apporter des modifications au contenu de l'EdS cible.
Trino est accessible dans K8S dans le namespace kosmos-data.
Accéder à la console K8S, choisir le namespace et accéder à la liste des pods. Choisir le pod du trino-coordinator et cliquer sur le bouton d'exécution' :
Résultat : la console est ouverte pour utiliser les commandes dans le pod Trino :
Annexe : Exemple d'exécution de requêtes sur deux catalogues Trino
Trino permet de faire des requêtes sur des EdS de stockage hétérogènes (au travers donc de ces catalogues). Pour cela, nous allons nous connecter avec un utilisateur qui a accès à plusieurs catalogues.
Créer un nouveau schéma sur un catalogue Minio pour contenir les références des données :
create schema catalogcroise;
Se connecter au schéma :
use catalogcroise;
Exemple d'une requête croisée sur plusieurs catalogues :
Il est indispensable de référencer le chemin complet des tables correspondantes, situées dans les catalogues accessibles à l'utilisateur.
Avant de faire le croisement nous pouvons réaliser un describe des différents catalogues en vue de regarder les colonnes en commun.
DESCRIBE mlapg.public.t_laposte;
DESCRIBE s3laposte.testvariable.s3laposte;
Nous pouvons réaliser la jointure entre les deux catalogues :
SELECT p.*, s.*
-> FROM mlapg.public.t_laposte p
-> JOIN s3laposte.testvariable.s3laposte s ON p.nom_commune = s.nomcommune;
Nous pouvons aussi spécifier le type de jointure qu'on veut réaliser :
SELECT p.nom_commune
-> FROM mlapg.public.t_laposte p
-> LEFT JOIN s3laposte.testvariable.s3laposte s ON p.nom_commune = s.nomcommune;