Overview
Introduction
KFlow is a workflow engine that allows you to declaratively define and run workflows on Kubernetes. KFlow has a simple API and YAML-based configuration. It has been designed with these characteristics in mind :
- extensibility, so that you can easily add new features and integrations ;
- recoverability, so that any failure during the execution of a workflow can be easily recovered ;
- decoupling from the underlying workflow engine and platform specifics ;
- distributed execution ;
- traceability of execution (audits, data lineage);
- ease of transfer from one execution environment to another ;
Each workflow in KFlow is defined according to one of the following two modes :
- An analytical mode built over PySpark, with extensions currently provided as Python functions and any library available in the PySpark environment. This mode is to be preferred for batch transformation of structured data ;
- A basic mode (also called flow mode), to be preferred for complex processing of unstructured data (documents, images) where each step of the workflow is executed in a container (in batch or continuous flow mode) with two runtimes provided for Python or Java developers.
Monitoring of Data Processing Execution is provided : volume of processed data, execution errors, errors in the data, processing report by step.
Object Model
The following diagram shows the object model of KFlow.
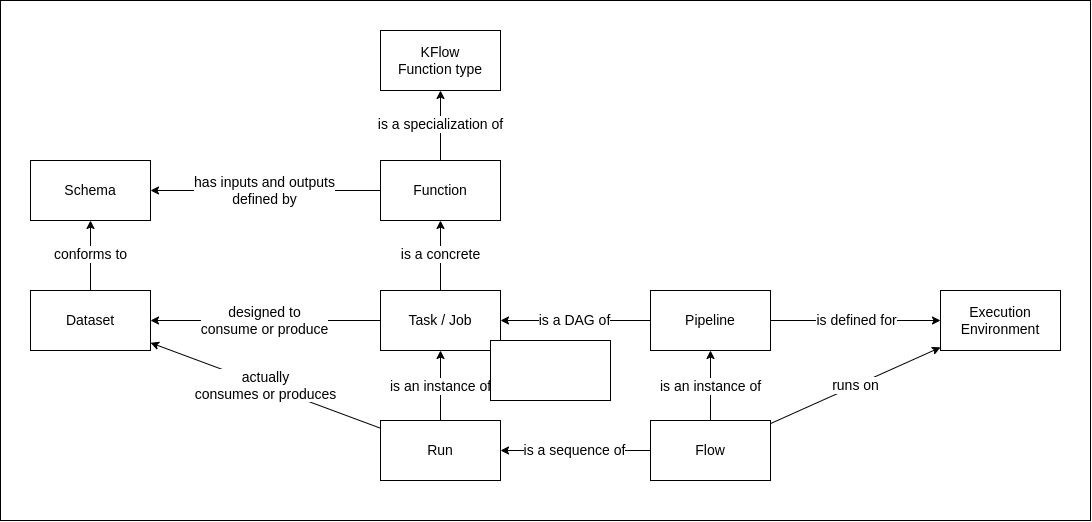
The Object Model of KFlow is designed to be compatible with the OpenLineage Object Model to ease an eventual integration with OpenLineage ecosystem in the future.
KFlow function type
A KFlow function type is a type of function that can be executed in a KFlow workflow. It can be a source, a sink, a transformation. Each function type limits the potential outcomes of the function. For example, a source function can only have outputs, a sink function can only have inputs, and a transformation function can have both inputs and outputs. We will see later that KFlow has a 'map' function type which maps each record of its single input to a record which is sent to all of its outputs. End users do not see the underlying function types, but only functions that are built over them by a platform engineer.
Function
A Function is a specialization of a KFlow function type. It has :
- A function type
- A list of potential inputs with schemas
- A list of potential outputs with schemas
- Some Control parameters
- A visual representation in the UI which helps users understand the function, and configure it (inputs, ouputs, control parameters)
Some functions are provided out of the box :
- Functions to read from or write to "raw" sources (S3, Kafka, SQL, OS) ;
- Functions provided as starting defaults (java runtime, python runtime, python scripting, sql queries, ...) to build other functions or tasks by specializing or extending those defaults.
New functions can be developed from scratch in Python or Java for complex processing (see Python Basic Runtime and Java Basic Runtime).
Task
A Task (or Job in OpenLineage) is an instance of a Function with concrete Datasets as inputs and outputs, and control parameters. A Task is defined through the UI, or in a YAML configuration file.
Pipeline
A Pipeline is a directed acyclic graph of Tasks. A Pipeline has a name, a description, and an execution environment. A Pipeline is defined through the UI, or with a set of YAML configuration file.
A Pipeline is sometimes refered to as a Topology in KFlow documentation and source code.
Flow and Run
A Flow is an instance of a Pipeline executed in the execution environment. It can be launched by a user that has not designed the Pipeline and do not have a full understanding of its inner workings. A Flow is launched programmatically with the KFlow API or through the UI. Every execution of a Task in a Flow is equivalent to a Run in the OpenLineage Object Model.