Administration Guides
Localisation
Le composant est déployé dans le cluster Kubernetes :
- namespace : kosmos-data-*
- pod : a748ed7ec-b47c-4923-9ef4-067c3ab1d1e3-860f6b-akco36q4sbfa-5dxql
- Exemple d'un flux en cours d'exécution
- pod : kflow-*
- worker temporal avec API REST
- pod : a748ed7ec-b47c-4923-9ef4-067c3ab1d1e3-860f6b-akco36q4sbfa-5dxql
- namespace : kosmos-data
- pod : datapipeline-ui-*
- IHM de l'application en React avec une API en GO
- pod : nats-*
- Transmission de donnée entre pods
- pod : temporal-admintools-*
- pod : temporal-frontend-*
- pod : temporal-history-*
- pod : temporal-matching-*
- pod : temporal-web-*
- pod : temporal-worker-*
- Moteur du data pipeline
- pod : datapipeline-ui-*
Configuration Initiale
Interfaces
Une IHM datapipeline-ui est exposée au travers d'un service kubernetes.
kubectl -n kosmos-data get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
datapipeline-ui ClusterIP 10.234.177.158 <none> 80/TCP 22d
Paramétrage spécifique
L'IHM datapipeline-ui fait des appels API aux services kflow des différents namespaces kosmos-data-* pour démarrer des flux qui effectuent des traitements.
Quand un flux démarre, le worker temporal crée des pods, déploiements, jobs ou configmaps dans les namespaces kubernetes kosmos-data-*, les éléments diffèrent selon le type de flux créé par l'utilisateur. Les éléments créés ont des noms commençant par l'ID du traitement. Cet ID est visible dans l'URL lorsqu'on se trouve dans l'IHM d'édition du traitement de datapipeline-ui. Les logs des pods démarrés pour un traitement sont récupéré par le code de datapipeline-ui et affichés dans l'IHM.
Fichiers clés
Fichiers de configuration
Beaucoup d'éléments de configuration sont contenu dans le configmap "datapipeline-ui" (version par defaut du runtime analytics utilisé, limite des CPU/RAM pour un flux analytic, liste des namespaces des API Kflow déployées, etc.)
kubectl -n kosmos-data get cm
Logs
En cas de problème pour démarrer un flux ou utiliser l'UI datapipeline-ui, les premiers logs à regarder sont ceux du pod datapipeline-ui du namespace kosmos-data. Puis dans un second temps il est possible de regarder les logs du pod kflow utilisé (si un utilisateur lance un flux bas, celui du namespace kosmos-data-bas). Puis en troisième intention celui du worker temporal du namespace kosmos-data (temporal-worker-*)
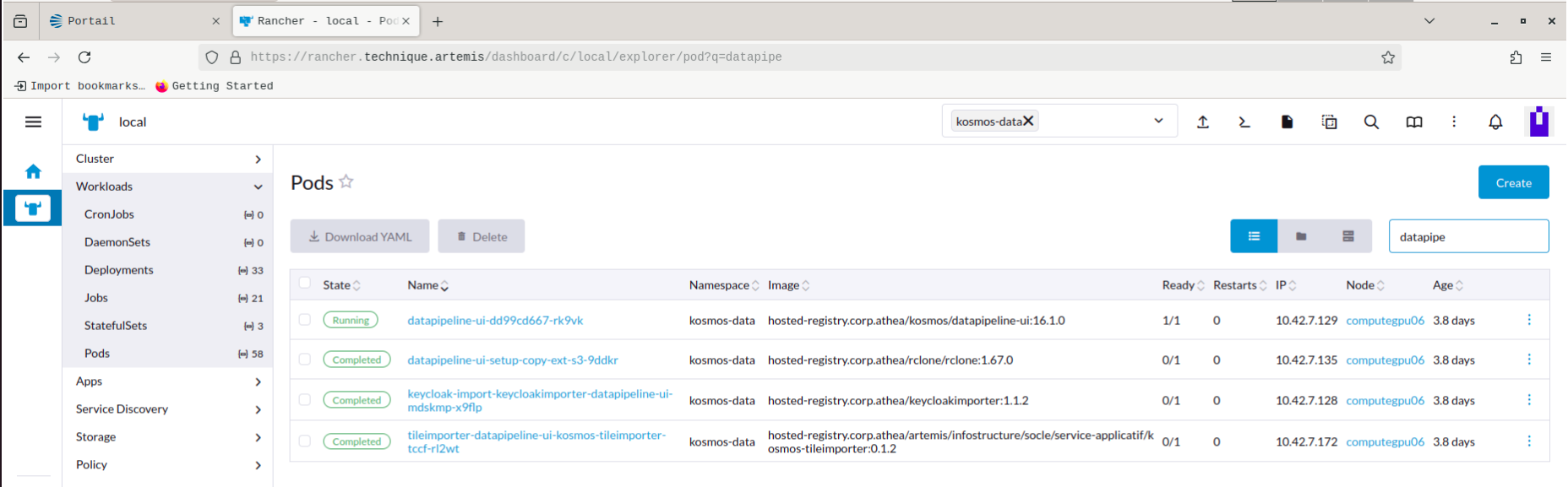
Etat du service
Vérifier l'état Running des pods depuis l'IHM de Rancher (namespace : kosmos-data)
Nettoyage flux plateforme
Cette procédure permet de nettoyer une plateforme de tout flux zombie. On appelle ici flux zombie tout flux qu'on ne parvient pas à couper à l'aide de l'IHM du Data Pipeline.
Le processus de création de ces flux zombie peut varier, les exemples les plus courant sont :
- le lancement+arrêt d'un flux trop rapidement en utilisant le mode de déploiement avancé
- le lancement d'un flux alors que la plateforme n'a pas assez de ressources disponibles
- le lancement d'un flux nécessitant une image qui n'est pas disponible sur la plateforme
Nettoyage des élément dans kubernetes
Si vous souhaitez arrêter un flux en particulier, dans l'IHM du Data Pipeline vous pouvez trouver l'ID du traitement dans l'URL depuis la vue d'édition du traitement. Sauf dans le cas d'un déploiement avancé où il faut récupérer la saisie faite par l'utilisateur pour personnaliser son nom du flux. Les noms des objets kubernetes à supprimer commenceront par cet ID de traitement.
Par exemple pour mon traitement ID a4a47def2-9e52-400a-9bc6-0aef036aa2be, un ID de flux possible serait a4a47def2-9e52-400a-9bc6-0aef036aa2be-56bdeb (sauf déploiement avancé).
Commencez par trouver le(s) namespace(s) où est(sont) installé(s) le(s) kflow(s). Le plus souvent les namespaces sont "kosmos-data-guest", "kosmos-data-bas", "kosmos-data-eid", "kosmos-data-prod"
Sur ce(s) namespace(s) trouvez les objets kubernetes correspondants à votre traitement. Si aucun objet ne correspond, passez à l'étape suivante.
kubectl get all -n {namespace} | grep {id_flux}
Supprimez les objets deploy et job kubernetes correspondant aux flux à l'aide des commandes kubectl delete :
kubectl delete job -n {namespace} a9cb22bf8-095d-4f97-80a5-83d9bdca810b-22f171
Il est possible de passer plusieurs id sur une même commande
Il est également possible de supprimer tout les objets d'un certain type, attention cependant à ne pas supprimer d'objet système. Vous pouvez par exemple utiliser la commande suivante pour supprimer tout les jobs d'un namespace
kubectl delete jobs --all -n kosmos-data-bas
Si après suppression les objets kubernetes sont recréés dynamiquement, passez à l'étape suivante.
Nettoyage dans le pod admintools de temporal
Trouvez le pod admintools de temporal et rentrez dedans en shell
kubectl get pod -A | grep temporal-admintools
kubectl exec -it -n {namespace} temporal-admintools-{ID_POD} -- sh
Lister les flux temporal en cours :
tctl wf la --open
Pour supprimer un flux avec les commandes temporal utilisez les commandes:
tctl wf term --workflow_id {workflow_id}
tctl wf c --workflow_id {workflow_id}
Ajuster les ressources de datapipeline-ui
Pour des raisons de sécurité (ne pas donner directement l'accès aux API Kube à un code exécuté côté client), les logs des traitements sont récupérés dans kubernetes et transmis au travers d'une API. Cette récupération nécessite de la RAM, qui est en quantité limitée dans le(s) pod(s) de datapipeline-ui
Cette procédure explique comment changer les différentes valeurs de ressources et de remontée de logs pour ajuster les ressources à votre usage.
Modifier le configmap
Pour contrôler les tailles et le nombre de lignes de logs retournés :
# sur plateforme Artemis
kubectl edit configmap -n kosmos-data datapipeline-ui
supervisionlog: # logs des flux terminés récupérés depuis la supervision (clickhouse)
maxLine: "100" # nombre de ligne maximale retournée pour une page (ces logs sont paginés)
maxLineSize: 1000 # taille maximale en caractère d'une ligne remontée
kubernetes: # logs des flux en cours récupérés depuis kubernetes (API interne kube)
logSizeOneLine: 4096 # taille maximale en caractère d'une ligne remontée
totalLogLines: 1000 # nombre maximale de lignes retournées, cette valeurs est divisée par le nombre de pods du flux
# digression sur les paramètress suivant:
cpuMax: 4000m
cpuMin: 100m
memoryMax: 8000Mi
memoryMin: 128Mi
defaultCpuLimit: 2000m
defaultCpuRequest: 200m
defaultMemoryLimit: 2048Mi
defaultMemoryRequest: 512Mi
# -> ces paramètres contrôlent les ressources par défaut des flux lancés depuis l'IHM, en aucun cas les ressources du pod datapipeline-ui
Redémarrer le pod de datapipeline-ui pour prendre en compte la modification :
kubectl rollout restart deploy -n kosmos-data datapipeline-ui
Modifier le déploiement
Pour contrôler la RAM et la CPU d'un pod datapipeline-ui dans un cas où beaucoup d'utilisateurs utilisent l'application :
- Passer en édition sur le déploiement de datapipeline-ui :
kubectl edit deploy -n kosmos-data datapipeline-ui
#section : spec.template.spec.containers(datapipeline-ui).ressources
limits:
cpu: 400m
memory: 1Gi
requests:
cpu: 200m
memory: 521Mi
Vérifier le bonne prise en compte
Le pod de datapipeline-ui a correctement redémarré
Ajout de replica au Data Pipeline
Cette procédure permet d'augmenter le nombre de pod du datapipeline-ui pour les plateformes avec de nombreux utilisateurs.
Par défaut le nombre de pod sur une installation standard est de 1. A partir d'une dizaine d'utilisateurs simultanés sur l'application ce nombre de pod n'est plus suffisant.
Modifier le déploiement
Se mettre en modification sur l'objet deploy du datapipeline-ui
# sur plateforme Artemis
kubectl edit deploy -n kosmos-data datapipeline-ui
Modifier la propriété spec.replicas :
spec:
replicas: 2
Vérifier le bonne prise en compte de l'augmentation du nombre de réplica
# sur plateforme ARTEMIS
kubectl get pod -n kosmos-data
# Résultat attendu
NAME READY STATUS RESTARTS AGE
copy-ext-s3-streamui-definitions-nsflz 0/1 Completed 0 21m
datapipeline-ui-548b99bb64-nbkzr 2/2 Running 1 (19m ago) 19m
datapipeline-ui-548b99bb64-rt5vv 2/2 Running 1 (4s ago) 11s